
Memo - On The Changing Dynamic Between Software & AI - April 2026
My 2-Cents in the Evolving Debate on the Future of Software

Hey everyone!
Hope everyone is doing well. For those celebrating this week and the next, happy holidays to you (also hopefully not getting too sick of my content…).
It is now almost one year since we began having a Substack here at 18 Degree Journal, and what a year it has been! We now have almost 100 subscribers (I guess I will have to follow up with the traditional acknowledgement in Substack notes once we hit it, per Substack's unofficial rules…), we have readers from 25 different nations (with about 150 regular unique readers!). So thank you so much to each and every one for your support, attention, and feedback. I appreciate you being part of the 18 Degree Journal, and I am excited for the improved content for years to come, as well as the connection we are making along the way. So, thank you and to more years ahead.
Back to the topic at hand, the last couple of months have introduced many stimulating discussions and debates about the future of the “AI” technologies and how they may shape our lives. There was a big debate on whether the SaaS (Software as a Service) businesses will be competed away, debates about the replacement of engineers (and other roles), fear over growing capex spending for the mega-scalers (with Oracle’s credit default swaps spiking in rates), and I’m sure you can extrapolate all the other growing fears surrounding “AI”. So I decided to try to add to the conversation to first capture how I am feeling in April 2026 (to avoid future biases impacting my worldview) and also to gauge how wrong or right I am. I think the field has been changing at an exponential rate, and the human brain struggles to keep up with the changing dynamics. Most of the growing fears surfaced with the release of the December 2025 models and with professionals adopting AI, seeing huge jumps in performance and efficiency, now being able to predict (or maybe over-predict) how it may affect us in the future.
I think from the get-go it's good to establish that it’s very hard to see how this field will grow, change, or where it may bottleneck. The future, as always, is uncertain and mysterious, but I'm of the strong belief that humans in any time period have unifying characteristics, and we may be able to make a few arguments with that in perspective. As for any expertise I may have, as some readers will know, I have a Bachelor’s in software engineering and have had the pleasure of working in the industry for years (granted, not a whole lot in the grand scheme of things). I have had the pleasure of touching a few technological sectors and interacting with many senior minds and debating this AI revolution, not to mention using these newfound tools now on a daily basis. Although my points may be naive, I can still bring forth my current understanding to the discussion.
I think the term AI has been thrown around a bit too much lately and a bit too loosely. So, for this article, whenever I mention AI or the protagonist of the essay, I'm referring to current generative AI technologies such as LLMs. To better constrain the conversation, I will break down each point into a sub-problem that generative AI is facing or the issue I have trouble seeing how it will solve. Otherwise, I feel the topics become too open-ended, and there is no systematic way to wrap my head around them.
I think a good way to set the tone for the conversation is to address the fundamental question of how we communicate, “What do we want?” Or to be more precise, how do we convey our request, vision, goals, and contain them in a box so that we may be able to produce it? To show a small issue an AI could have with this, I'll take you back to my university days. I remember when I was still in university, I took a requirements engineering course. This course centers around how to produce requirement documents (aka documents that encompass the client's request to produce a product). The hardest part of the class and the biggest glaring warning the professor would emphasize is that most of the time, your client doesn't yet know fully what they want, not to mention not being able to communicate it. Moreover, there are numerous other issues that come with working with clients, such as scope creep (when the expected product scope keeps containing more and more features), changing requirements, miscommunications, etc. These lessons and insights carried over to my personal experiences, whether it was producing software for clients, working with managers within an organization, or even working on a personal project (…oops). Now we introduce a new abstraction level for natural language AI that takes your plain English request and determines the right coding language abstraction to produce your vision…Who is to say what you asked for is the right thing? There is a lesson that most computer science/software engineers learn early: that computers, by essence, are not smart; they do what you tell them to do, how you tell them to do it. The current Gen-AI is a lot more sophisticated than this understanding, but at the end of the day, it still relies heavily on proper communication to get your mission across. Who is to say the vision you presented is accurate or that the different levels of abstraction captures what you needed? Steve Jobs famously said, “People don’t know what they want until you show it to them”. A Gen-AI that is prompted to act by a user is not meant to overreach and create a new vision; it's there to find the average best representation of what you have described at the time you described it. Also, to come back to my main point on customers introducing new visions that dilute requirements or evolving a product into some sort of mutation of the original idea, a Gen-AI is not really meant to be pushing back against the production, yes we can put guard rails, questions about priorities, etc., but all of that is useless if a client can override and force their way (true with live engineers but I don’t think its quite the same).
Now, if we can nail down this communication and vision layer, my next question is: “If something goes wrong or is not as expected, whose responsibility is it?” Say we purchase a product from a vendor or have an internal team make a product, when things go wrong, there is always a responsible party, one that will take the heat, try to fix the issue, or in some cases take the downfall for the issue (sadly human structure especially in private sector leads to people getting the short end of the stick). Now we can argue the person who delegated the task to the AI, the creator of the AI, or perhaps the vendor of the AI, takes the blame, but I think this structure would not be sustainable, and management and the firm will want more layers of responsibility (for some to selfishly protect themselves from blame). The reality of many enterprises, especially software enterprises, lives in an ecosystem of a lot of different moving and evolving parts, and something constantly changes in a way that will break your systems, especially if you have technical debt (everyone has some), and issues are completely unavoidable (especially with malicious actors always trying to break [into?] things). I am having a lot of trouble seeing an automation of a lot of processes because I can't map out the responsibility question, and a way around any of the social fragility of corporate structures. Other than the responsibility and blame game, I think Gen-AI systems introduce non-deterministic problems that are a lot harder to audit, reproduce, or find what component to blame, since Gen-AI output itself is not consistent (aka not the exact same output) it introduces a novel issue of not being able to reproduce all issues the system found In my view this could add another complexity on existing blame game dynamics.
I think a conversation about Gen-AI, especially today, requires a look at what risks and compromises you accept when using it exclusively. When using Gen-AI technology, such as an LLM, you are essentially working with a large collection of data, trying to find the most probable output for each request. This process itself is a collection of statistical problems, and the output varies in ways that is statistically bounded but not guaranteed, meaning that you are likely to generate the same or similar output, but you will not necessarily get it. I'm going to better illustrate it (there's an image below), but you are working within a frame of a bell curve. Engineers are working hard to shift your average output as much as possible toward quality while reducing variance. However, the whole driver of improved LLM output has been a drive for larger models with larger context windows (according to recent studies I read, having a strong positive relationship with model size and model output). This means these huge foundational models built largely on global internet data are exposed to not the best quality of information, increasing the difficulty to improve the “average” of average internet data. On top of that, you are significantly bottlenecked in your ability to utilize these tools to their best potential in order to even guarantee the best possible output to generate from them. I think we all noticed that people use Gen AI in different capacities and with different levels of understanding. I think the current latter framework is the best in grouping different classes of users:
Level 1 User: Uses Chat Function (Q&A format). Conversational use, quick answers, casual prompting. Treats the Gen-AI like a search engine.
Level 2 User: Uses LLMs for task delegation. Uses it to draft documents, summarizing content, or generating content (such as email, Excel files, reports). Usually this user is more familiar with the basics of improving output with proper prompting and formatting as well as aware of double-checking output.
Level 3 User: Uses Gen-AI for workflow integration. Embeds AI into their process, such as advanced autofill (like code completion), uses tools, APIs, and chained prompts. Thinks about outputs critically and knows how to set the domain of the model and context to shift the curve toward their domain and catered output. Is somewhat informed about the limitations of output and tries to minimize output pitfalls.
Level 4 User: Uses different agentic/autonomous processes. Multi-step pipelines, coding agents, and build systems with AI. Understands limitations deeply and is constantly experimenting with better utilization techniques. Knows how to create a systematic approach to generate output and sets limits to the context.
Level 5 — The Pro Users. They know or do fine-tuning and architecture on their models. They shape the model itself, use their own custom datasets, and specialize in deployments. Borderline experts to be able to create their very own Gen-AI Tools.
Of course, this model is not all-encompassing and has its own limitations as a framework to understand the different categories of users. But the frameworks allow us to understand that there are “levels” to using Gen-AI, and most users are not maximizing their potential output when using these tools. What this leads me to think is how averse most corporations and people are to change, especially when the status quo works. So it's very hard for me to imagine a huge incentive for average workers and organizations to optimize using these tools to actually achieve the best possible results they can. Along the same line, you may have noticed that more services are likely facing significant downtime, especially those services that are relying on AI automation and are making some reliability mistakes. Part of the problem stems from how these tools are applied, and the majority of users operating these tools well below the level needed to extract consistent, high-quality output (The majority of professionals who have transitioned to using Gen AI tools operate at Level 1 and Level 2). The other part (without going into tremendous detail) is the structural ceiling given by context windows (and LLMs prioritizing context in the context window). For its parts and practical purposes, the majority of the best output in Gen AI is produced within a very limited scope (a small problem), and once a large complex problem is introduced, the output seems to fall short. The LLM’s probabilistic nature currently prevents it from handling large, complex problems. I think this issue is deeply connected to the fact that you are only limited to the average output, and the dataset of code you are trained on contains bad code; your average output is contradicted by the ratio of good to bad code, and with plenty of bad quality samples, it anchors your average output. Many of the best lines of code are written by fantastic, amazing engineers whose output is incomparable to the average… There is a good reason that top-performing engineers are sometimes paid more than some CEOs.
I've been discussing the frontier Gen-AI tool, but what might the future hold for them? Well, I have a strong conviction that as this field progresses, the current Gen AI tools will converge more and more toward a similar experience and output. So today, having frontier companies such as Anthropic, OpenAI, Google, QWEN (Alibaba), Kimi, Mistral, etc., are all training on the biggest dataset we have…the internet or in some cases (cough cough) on each other, summarization or structure on internet data. The differentiating factor in how they fine-tune and optimize their models is very limited, and with the ability to replicate any secondary toolkit, the competition will, over time, converge into an undifferentiated product. Even today, anecdotally many users are sticking to one or two products and are not incentivized to switch as the products themselves are not that different. Now with that out of the way, say we agree for a moment that development work and other automated work do get automated on the software side, is it no longer viable to build any software businesses or products? Well, I'll have my comment about the SaaS business in the next section, but for development, I want to say it may not be dead, but it just might have different priorities. As a user who has been using AI from almost the beginning of its public release, I can confidently identify AI elements on websites, in writing, and in general content generation — and if we extrapolate this commoditization of models and the automation of creation of products. I think everything will return to first principles software, and other programs will still very much exist, but the Steve Jobs artist factor (the ability to build unique, different experiences) will become the dominant factor driving the industry. On the internet, worry of whether or not AI will “make the art while humans wash the dishes,” I am of the strong opinion that the human element of taste, art, and fashion will drive the next wave of product uses. In a world where functionality gets commoditized by generative AI, the user's feeling of a product's uniqueness will be the main magnet (well, that and the network effect of having a lot of individuals on a platform driving more users…). I think this taste and art feeling is severely overlooked. Jimmy Iovine was on David Senra's podcast (goated podcast you need to check out, here is the episode:
) and made the excellent point that AI will enable the mediocre to be better, but the true artist with taste will excel regardless, and I think this is the case with any new technologies, the true artist will be enabled by this technological revolution, the commoditization might happen to the functionality of the product, but not their experiences. Why don’t I believe that this creativity can be automated away? Well Gen-AI systems are trained on datasets of past history , to use a cliché, are always looking in the rear view mirror, and can only synthesize from what was already produced. yes, yes you can tweak parameters to induce hallucination creative behaviour but it's still a statistical recombination, in contrast a true artist, who creates from genuine feeling, often without logic or any justification has a competitive advantage that no autonomous system can replicate. Maybe my last analogy I want to bring forward (I promise I’m about to move on…) is from history, but I see similarities between the production of AI vibe-coded software and the saturation of the Video Game market back in the 80s. In the 80s once video games were shown to be a profitable enterprise the market became flooded with cheap, bad products to force the quantity sales of as many software games as possible…leading to the complete collapse of the video game industry until Nintendo brought it back with the Nintendo seal of approval of games this seal demonstrating quality brought consumers back to buying video game products. The production of AI products will do the same; the quality product will continue to thrive once the average vibe-coded product slowly dies.
Well, I think we covered a lot of the main points I wanted to touch on before getting to the hottest topic of February: whether the SaaS business model is dead or gone (or restructured). Again, we are circling back to the argument above about the commoditization of software, but here I want to take a slightly different angle (also, um, I will probably, in one form or another, repeat some of the points spread across other sections). I think there’s a disconnect between understanding why the SaaS business model grew so fast and why it hasn’t really been disrupted by other models. Traditionally, when a company wanted to develop a feature or function, they would invest in an expensive, slow process with a dedicated team to develop that product for each and every feature they needed. This also means a dedicated developer to maintain that one functionality, improve it and take responsibility for it. SaaS abstracted this and solved it by allowing a business to come in, take on that one specific feature, build maintenance on it, and sell the same solution across multiple businesses and therefore bring per business under service costs way down, in turn boom large margins for the SaaS business as marginal additions of new businesses needed to one function cost almost nothing as the product is already developed. Again, the process of developing a feature or function and maintaining it for one client is expensive and a very low-margin business, but going out and selling the same or very similar product to other companies is what allows SaaS businesses to really make money. So if we now take this back to teams managing and creating their own internal function, you are bringing it back to each team to spend on the same function, and assuming per seat in a Gen-AI would replace the quality or output of the function (also one subscription for another, although it seems people forget that tokens are limited or charged for). Now I get the argument: you could have a copycat product showing the same exact product, but the switching costs of habits and restarting are massive and very hard to push for in bigger companies. The accountability, trust, and assurances of existing solutions often outweigh the reputation of new incumbents. Furthermore, it seems like a lot of the time we are forgetting existing SaaS companies can optimize with the same Gen-AI to systematically bring down some of their own costs and perhaps evolve their business to slightly worse economics by passing savings to consumers, but it’s still a very much sustainable business model as long as scale reduces costs.
Although a lot of the ideas I presented have been issues, I'm having trouble wrapping my head around explaining Gen-AI replacement. I wanted to spend a small part talking about another notion I have been mulling over: whether we are moving toward a future where Gen-AI models are run on local devices. If we look today, we already have both existing and impressive capacity. Heck, I am writing this article on my MacBook Pro, which can run a decent small/medium model by itself (enough for level 1-3 users, maybe Level 4?) and has worked with an industrial-grade GPU, so it can really fly through local models. This capacity of course is not super cheap and comes with its own limitations, but the fact that we are already running very decent local Gen AI tools may foreshadow what our future might look like. However, even when I extrapolate how the future might look, I am troubled by the physics that may make local models less meaningful for professionals (aka your phone, watch, non-fully-built desktop PCs, or even notebooks). So far, scaling laws have been pretty fairly unambiguous; larger models produce meaningfully better output, and the energy and physical surface area required to reproduce that output have consistently favoured data center infrastructure over local hardware. The smaller the components and the more power they need to reproduce the same output, physics and thermodynamics dictate that an immense amount of headroom would be required on the chip, and I can't imagine the hardware cost of small, perfectly moulded components will be more than a larger chip with similar characteristics. So, say we take an extreme example of having a local LLM on a smartwatch, the watch’s hardware hits a ceiling determined by heat dissipation and die size, limiting what you can physically put on it, and the argument that we really need it to be placed on such a small chip to my head doesn’t make sense. Say we take the same watch and instead of locally it’s just ping a server with your request, the difference in experience changed simply by latency is almost negligible (it would take a few milliseconds for the request to travel from your watch to the server and back…), not to even mention that your request will be processed better on server hardware…. I don’t think there are many applications where there is a requirement for real-time production of output (some applications that do require it could be self-driving, surgery assistance systems) and the only other logical constraint could be privacy concerns. But in this case I just invented more personalized hardware and similar smaller scale servers per organization requiring the local interfacing. Of course, there are exceptions such as remote areas or failsafe systems needing local output, but a realistic world where the best output is produced in the cloud and served to consumers with failsafe local systems seems to be the most realistic version of the future reality to me, and I think in the future the majority of Gen AI computation is completed in the cloud.
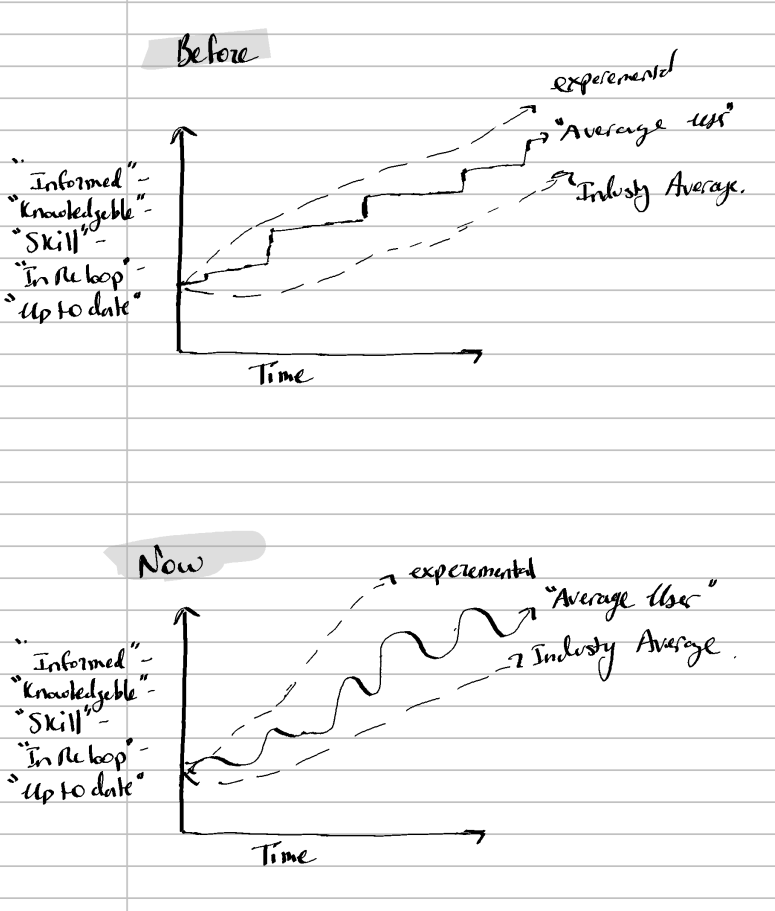
Before I close my article, I did want to add some remarks on how these AI generative technologies have been integrated into my workspace and my feelings about them. First, I want to say agentic coding agents, especially in the last couple of months, are extremely revolutionary, they allow me to do so much more and find a lot of my mistakes in my production and sometimes in real time. It has been extremely helpful and has saved me hours of time. You may assume that, since it saves me hours of work, I may be working less. However, the more I rely on these tools, the longer my workday gets. The coding agents are a huge enabler of touching more parts of my project at the same time, meaning as I become better, I'm doing bigger parts of the project in a shorter time, and usually leading me to have longer days to get those parts across the finish line, only to restart the next day. So, as to the perfect metaphor, the coding agents have become a sort of double-edged sword. The other notion is that the field is progressing extremely fast. The number of papers I have to constantly follow to understand newfound limitations of current implementation of generative AI, or better methods to use it, is constantly growing, not to mention the bombardment of constant new tools, tips and tricks to get better at using current offerings. At times, it can be overwhelming, but it's a constant balancing act between being behind and being informed. I think many are burned out, and we are starting to see a wave-like progression in informed users (better to say, up-to-date users). What do I mean? Well, for lack of a better way to explain it, I think the pattern of individual developers and users of these platforms is: The general user of generative AI technologies is informed on a wave with peaks and troughs of being in the loop vs before. I felt the pattern resembled a wave, where you ride it up (your catching up to status quo) and down (to much information comes out and you fall behind).
Well….. I hope that was somewhat comprehendible, still working on getting my communication to a better level. I am excited to see how wrong I turn out to be in my assessment. The world is changing really quickly, and I am sure there are many things I will not see until it slams me in my face. There is definitely a lot I wasn't able to say in this piece or capture in some of the nuances, like, for example, the biases introduced by Reinforcement Learning from Human Feedback (RLHF), hallucination of output introducing false or inaccurate information, the energy or environmental costs as well as any intellectual property issues, or the compounding issues of compounding error problems in agentic systems, but I hope I prioritized some of my main ideas. I think I am fortunate (hopefully not unfortunate) to live through the monumental evolution in our tools; I think it is one of the greatest inventions and will lead to many great advancements in the future. Thank you for reading, and I hope you enjoy some of my thoughts. Feel free to DM me to debate or comment below. Always nice to talk to readers and guests,
Cheers!
Daniel Andreev - 18 Degree Journal